NCAR JupyterHub Large Data Example Notebook
Note: If you do not have access to the NCAR machine, please look at the AWS-LENS example notebook instead.
This notebook demonstrates how to compare large datasets on glade with ldcpy. In particular, we will look at data from CESM-LENS1 project (http://www.cesm.ucar.edu/projects/community-projects/LENS/data-sets.html). In doing so, we will start a DASK client from Jupyter. This notebook is meant to be run on NCAR’s JupyterHub (https://jupyterhub.hpc.ucar.edu). We will use a subset of the CESM-LENS1 data on glade is located in /glade/campaign/cisl/asap/ldcpy_sample_data/lens.
We assume that you have a copy of the ldcpy code on NCAR’s glade filesystem, obtained via: git clone https://github.com/NCAR/ldcpy.git
When you launch a NCAR JupyterHub session, you will need to indicate a machine and then you will need your charge account. You can then launch the session and navigate to this notebook.
NCAR’s JupyterHub documentation: https://www2.cisl.ucar.edu/resources/jupyterhub-ncar
Here’s another good resource for using NCAR’s JupyterHub: https://ncar-hackathons.github.io/jupyterlab-tutorial/jhub.html)
You can run your notebook with the “NPL 2023a” kernel (choose from the dropdown in the upper left.)
Note that the compressed data that we are using was generated for this paper:
Allison H. Baker, Dorit M. Hammerling, Sheri A. Mickelson, Haiying Xu, Martin B. Stolpe, Phillipe Naveau, Ben Sanderson, Imme Ebert-Uphoff, Savini Samarasinghe, Francesco De Simone, Francesco Carbone, Christian N. Gencarelli, John M. Dennis, Jennifer E. Kay, and Peter Lindstrom, “Evaluating Lossy Data Compression on Climate Simulation Data within a Large Ensemble.” Geoscientific Model Development, 9, pp. 4381-4403, 2016 (https://gmd.copernicus.org/articles/9/4381/2016/)
Setup
Let’s set up our environment. First, make sure that you are using an appropriate kernel (like NPL 2023a). Then you will need to modify the path below to indicate where you have cloned ldcpy.
If you want to use the dask dashboard, then the dask.config link must be set below (modify for your path in your browser).
[1]:
# Add ldcpy root to system path (MODIFY FOR YOUR LDCPY CODE LOCATION IF NOT IN the kernel)
import sys
# sys.path.insert(0, '/glade/u/home/abaker/repos/my_ldcpy')
sys.path.insert(0, '../../../')
import ldcpy
# Display output of plots directly in Notebook
%matplotlib inline
# Automatically reload module if it is editted
%reload_ext autoreload
%autoreload 2
# silence warnings
import warnings
warnings.filterwarnings("ignore")
Connect to DASK distributed cluster :
Since we use the PBS Pro scheduler at NCAR, we will use the PBSCluster scheduler from dask-jobqueue. Initialization is similar to a LocalCluster, but with unique parameters specific to creating batch jobs. Helpful info about using DASK at NCAR: https://github.com/NCAR/Xarray-Dask-ESDS-2024/blob/main/notebooks/02-dask-intro.ipynb
[2]:
import dask
from dask_jobqueue import PBSCluster
You’ll need to customize the parameters of the PBSCluster template for the resources that will be assigned to each batch job.
[3]:
cluster = PBSCluster(
# Basic job directives
job_name='ldcpy-largedata',
queue='casper',
walltime='60:00',
# Make sure you change the project code if running this notebook!!
account='NTDD0004',
log_directory='dask-logs',
# These settings impact the resources assigned to the job
cores=1,
memory='10GiB',
resource_spec='select=1:ncpus=1:mem=10GB',
# These settings define the resources assigned to a worker
processes=1,
# This controls where Dask will write data to disk if memory is exhausted
local_directory='/local_scratch/pbs.$PBS_JOBID/dask/spill',
# This specifies which network interface the cluster will use
interface='ext',
)
Check your job script:
[4]:
print(cluster.job_script())
#!/usr/bin/env bash
#PBS -N ldcpy-largedata
#PBS -q casper
#PBS -A NTDD0004
#PBS -l select=1:ncpus=1:mem=10GB
#PBS -l walltime=60:00
#PBS -e dask-logs/
#PBS -o dask-logs/
/glade/u/apps/opt/conda/envs/npl-2024a/bin/python -m distributed.cli.dask_worker tcp://128.117.208.118:36515 --nthreads 1 --memory-limit 10.00GiB --name dummy-name --nanny --death-timeout 60 --local-directory /local_scratch/pbs.$PBS_JOBID/dask/spill --interface ext
We’ve created a cluster using PBSCluster(), and now we need Dask to provide an object called the Client for interacting with the cluster and workers.
[5]:
from dask.distributed import Client
# Attach a "client" to our created cluster
client = Client(cluster)
# Display the client repr
client
[5]:
Client
Client-cee87cd0-97cd-11ef-851e-ac1f6bab1e16
| Connection method: Cluster object | Cluster type: dask_jobqueue.PBSCluster |
| Dashboard: https://jupyterhub.hpc.ucar.edu/stable/user/abaker/proxy/8787/status |
Cluster Info
PBSCluster
07d66607
| Dashboard: https://jupyterhub.hpc.ucar.edu/stable/user/abaker/proxy/8787/status | Workers: 0 |
| Total threads: 0 | Total memory: 0 B |
Scheduler Info
Scheduler
Scheduler-a041bbd3-14db-4d2b-a3d7-6856b1332ee9
| Comm: tcp://128.117.208.118:36515 | Workers: 0 |
| Dashboard: https://jupyterhub.hpc.ucar.edu/stable/user/abaker/proxy/8787/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
[6]:
# Scale the cluster to some number of workers
# cluster.scale(10)
# Block progress until workers have spawned (optional - typically only in demos and benchmarks!)
# cluster.wait_for_workers(10)
# or adaptively
cluster.adapt(minimum_jobs=1, maximum_jobs=20)
[6]:
<distributed.deploy.adaptive.Adaptive at 0x14f6448d5dd0>
[7]:
cluster.workers
[7]:
{}
[8]:
# See the workers in the job scheduler
!qstat -u $USER
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
2888258.casper* abaker jhublog* cr-login-* 22945 1 1 4gb 720:0 R 01:04
2888642.casper* abaker htc ldcpy-lar* 29869 1 1 10gb 01:00 R 00:06
The sample data on the glade filesystem
In /glade//cisl/asap/ldcpy_sample_data/lens on glade, we have TS (surface temperature), PRECT (precipiation rate), and PS (surface pressure) data from CESM-LENS1. These all all 2D variables. TS and PRECT have daily output, and PS has monthly output. We have the compressed and original versions of all these variables that we would like to compare with ldcpy.
First we list what is in this directory (two subdirectories):
[9]:
# list directory contents
import os
os.listdir("/glade/campaign/cisl/asap/ldcpy_sample_data/lens")
[9]:
['README.txt', 'lossy', 'orig']
Now we look at the contents of each subdirectory. We have 14 files in each, consisting of 2 different timeseries files for each variable (1920-2005 and 2006-2080).
[10]:
# list lossy directory contents (files that have been lossy compressed and reconstructed)
lossy_files = os.listdir("/glade/campaign/cisl/asap/ldcpy_sample_data/lens/lossy")
lossy_files
[10]:
['c.FLUT.daily.20060101-20801231.nc',
'c.CCN3.monthly.192001-200512.nc',
'c.FLNS.monthly.192001-200512.nc',
'c.LHFLX.daily.20060101-20801231.nc',
'c.TS.daily.19200101-20051231.nc',
'c.SHFLX.daily.20060101-20801231.nc',
'c.U.monthly.200601-208012.nc',
'c.TREFHT.monthly.192001-200512.nc',
'c.LHFLX.daily.19200101-20051231.nc',
'c.TMQ.monthly.192001-200512.nc',
'c.PRECT.daily.20060101-20801231.nc',
'c.PS.monthly.200601-208012.nc',
'c.Z500.daily.20060101-20801231.nc',
'c.FLNS.monthly.200601-208012.nc',
'c.Q.monthly.192001-200512.nc',
'c.U.monthly.192001-200512.nc',
'c.CLOUD.monthly.192001-200512.nc',
'c.so4_a2_SRF.daily.20060101-20801231.nc',
'c.PRECT.daily.19200101-20051231.nc',
'c.TAUX.daily.20060101-20801231.nc',
'c.CLOUD.monthly.200601-208012.nc',
'c.TS.daily.20060101-20801231.nc',
'c.FSNTOA.daily.20060101-20801231.nc',
'c.Q.monthly.200601-208012.nc',
'c.CCN3.monthly.200601-208012.nc',
'c.TREFHT.monthly.200601-208012.nc',
'c.TMQ.monthly.200601-208012.nc',
'c.PS.monthly.192001-200512.nc']
[11]:
# list orig (i.e., uncompressed) directory contents
orig_files = os.listdir("/glade/campaign/cisl/asap/ldcpy_sample_data/lens/orig")
orig_files
[11]:
['CLOUD.monthly.200601-208012.nc',
'LHFLX.daily.20060101-20801231.nc',
'so4_a2_SRF.daily.20060101-20801231.nc',
'PRECT.daily.20060101-20801231.nc',
'TMQ.monthly.192001-200512.nc',
'TAUX.daily.20060101-20801231.nc',
'CCN3.monthly.200601-208012.nc',
'PS.monthly.192001-200512.nc',
'FLUT.daily.20060101-20801231.nc',
'PRECT.daily.19200101-20051231.nc',
'TS.daily.20060101-20801231.nc',
'PS.monthly.200601-208012.nc',
'TS.daily.19200101-20051231.nc',
'Z500.daily.20060101-20801231.nc',
'SHFLX.daily.20060101-20801231.nc',
'Q.monthly.200601-208012.nc',
'TMQ.monthly.200601-208012.nc',
'U.monthly.200601-208012.nc',
'FSNTOA.daily.20060101-20801231.nc',
'TREFHT.monthly.200601-208012.nc',
'FLNS.monthly.192001-200512.nc',
'FLNS.monthly.200601-208012.nc']
We can look at how big these files are…
[12]:
print("Original files")
for f in orig_files:
print(
f,
" ",
os.stat("/glade/campaign/cisl/asap/ldcpy_sample_data/lens/orig/" + f).st_size / 1e9,
"GB",
)
Original files
CLOUD.monthly.200601-208012.nc 3.291160567 GB
LHFLX.daily.20060101-20801231.nc 4.804299285 GB
so4_a2_SRF.daily.20060101-20801231.nc 4.755841518 GB
PRECT.daily.20060101-20801231.nc 4.909326733 GB
TMQ.monthly.192001-200512.nc 0.160075734 GB
TAUX.daily.20060101-20801231.nc 4.856588097 GB
CCN3.monthly.200601-208012.nc 4.053932835 GB
PS.monthly.192001-200512.nc 0.12766304 GB
FLUT.daily.20060101-20801231.nc 4.091392046 GB
PRECT.daily.19200101-20051231.nc 5.629442994 GB
TS.daily.20060101-20801231.nc 3.435295036 GB
PS.monthly.200601-208012.nc 0.111186435 GB
TS.daily.19200101-20051231.nc 3.962086636 GB
Z500.daily.20060101-20801231.nc 3.244290942 GB
SHFLX.daily.20060101-20801231.nc 4.852980899 GB
Q.monthly.200601-208012.nc 3.809397495 GB
TMQ.monthly.200601-208012.nc 0.139301278 GB
U.monthly.200601-208012.nc 4.252600112 GB
FSNTOA.daily.20060101-20801231.nc 4.101201335 GB
TREFHT.monthly.200601-208012.nc 0.110713886 GB
FLNS.monthly.192001-200512.nc 0.170014618 GB
FLNS.monthly.200601-208012.nc 0.148417532 GB
Open datasets
First, let’s look at the original and reconstructed files for the monthly surface Pressure (PS) data for 1920-2006. We begin by using ldcpy.open_dataset() to open the files of interest into our dataset collection. Usually we want chunks to be 100-150MB, but this is machine and app dependent.
[13]:
# load the first 86 years of monthly surface pressure into a collection
col_PS = ldcpy.open_datasets(
"cam-fv",
["PS"],
[
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/orig/PS.monthly.192001-200512.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/lossy/c.PS.monthly.192001-200512.nc",
],
["orig", "lossy"],
chunks={"time": 500},
)
col_PS
dataset size in GB 0.46
[13]:
<xarray.Dataset>
Dimensions: (collection: 2, time: 1032, lat: 192, lon: 288)
Coordinates:
* lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
* time (time) object 1920-02-01 00:00:00 ... 2006-01-01 00:00:00
cell_area (lat, collection, lon) float64 dask.array<chunksize=(192, 1, 288), meta=np.ndarray>
* collection (collection) <U5 'orig' 'lossy'
Data variables:
PS (collection, time, lat, lon) float32 dask.array<chunksize=(1, 500, 192, 288), meta=np.ndarray>
Attributes: (12/16)
Conventions: CF-1.0
source: CAM
case: b.e11.B20TRC5CNBDRD.f09_g16.031
title: UNSET
logname: mickelso
host: ys0219
... ...
history: Tue Nov 3 13:51:10 2020: ncks -L 5 PS.monthly.192001-2...
NCO: netCDF Operators version 4.7.9 (Homepage = http://nco.s...
cell_measures: area: cell_area
data_type: cam-fv
file_size: {'orig': 127663040, 'lossy': 39865015}
weighted: TrueData comparison
Now we use the ldcpy package features to compare the data.
Surface Pressure
Let’s look at the comparison statistics at the first timeslice for PS.
[14]:
ps0 = col_PS.isel(time=0)
ldcpy.compare_stats(ps0, "PS", ["orig", "lossy"])
| orig | lossy | |
|---|---|---|
| mean | 98509 | 98493 |
| variance | 8.4256e+07 | 8.425e+07 |
| standard deviation | 9179.1 | 9178.8 |
| min value | 51967 | 51952 |
| min (abs) nonzero value | 51967 | 51952 |
| max value | 1.0299e+05 | 1.0298e+05 |
| probability positive | 1 | 1 |
| number of zeros | 0 | 0 |
| 99% real information cutoff bit | 19 | 19 |
| spatial autocorr - latitude | 0.98434 | 0.98434 |
| spatial autocorr - longitude | 0.99136 | 0.99136 |
| entropy estimate | 0.40644 | 0.11999 |
| lossy | |
|---|---|
| max abs diff | 31.992 |
| min abs diff | 0 |
| mean abs diff | 15.906 |
| mean squared diff | 253.01 |
| root mean squared diff | 18.388 |
| normalized root mean squared diff | 0.0003587 |
| normalized max pointwise error | 0.00062698 |
| pearson correlation coefficient | 1 |
| ks p-value | 1.6583e-05 |
| spatial relative error(% > 0.0001) | 69.085 |
| max spatial relative error | 0.00048247 |
| DSSIM | 0.91512 |
| file size ratio | 3.2 |
Now we make a plot to compare the mean PS values across time in the orig and lossy datasets.
[15]:
# comparison between mean PS values (over the 86 years) in col_PS orig and lossy datasets
ldcpy.plot(col_PS, "PS", sets=["orig", "lossy"], calc="mean")

Now we instead show the difference plot for the above plots.
[16]:
# diff between mean PS values in col_PS orig and lossy datasets
ldcpy.plot(col_PS, "PS", sets=["orig", "lossy"], calc="mean", calc_type="diff")

We can also look at mean differences over time. Here we are looking at the spatial averages and then grouping by day of the year. If doing a timeseries plot for this much data, using “group_by” is often a good idea.
[17]:
# Time-series plot of mean PS differences between col_PS orig and col_PS lossy datasets grouped by month of year
ldcpy.plot(
col_PS,
"PS",
sets=["orig", "lossy"],
calc="mean",
plot_type="time_series",
group_by="time.month",
calc_type="diff",
)

[18]:
# Time-series plot of PS mean (grouped by month) in the original and lossy datasets
ldcpy.plot(
col_PS,
"PS",
sets=["orig", "lossy"],
calc="mean",
plot_type="time_series",
group_by="time.month",
)

[19]:
del col_PS
Surface Temperature
Now let’s open the daily surface temperature (TS) data for 1920-2005 into a collection. These are larger files than the monthly PS data.
[20]:
# load the first 86 years of daily surface temperature (TS) data
col_TS = ldcpy.open_datasets(
"cam-fv",
["TS"],
[
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/orig/TS.daily.19200101-20051231.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/lossy/c.TS.daily.19200101-20051231.nc",
],
["orig", "lossy"],
chunks={"time": 500},
)
col_TS
dataset size in GB 11.10
[20]:
<xarray.Dataset>
Dimensions: (collection: 2, time: 25100, lat: 192, lon: 288)
Coordinates:
* lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
* time (time) object 1920-01-01 00:00:00 ... 1988-10-07 00:00:00
cell_area (lat, collection, lon) float64 dask.array<chunksize=(192, 1, 288), meta=np.ndarray>
* collection (collection) <U5 'orig' 'lossy'
Data variables:
TS (collection, time, lat, lon) float32 dask.array<chunksize=(1, 500, 192, 288), meta=np.ndarray>
Attributes: (12/16)
Conventions: CF-1.0
source: CAM
case: b.e11.B20TRC5CNBDRD.f09_g16.031
title: UNSET
logname: mickelso
host: ys0219
... ...
history: Tue Nov 3 13:56:03 2020: ncks -L 5 TS.daily.19200101-2...
NCO: netCDF Operators version 4.7.9 (Homepage = http://nco.s...
cell_measures: area: cell_area
data_type: cam-fv
file_size: {'orig': 3962086636, 'lossy': 1330827000}
weighted: TrueLook at the first time slice (time = 0) statistics:
[21]:
ldcpy.compare_stats(col_TS.isel(time=0), "TS", ["orig", "lossy"])
| orig | lossy | |
|---|---|---|
| mean | 284.49 | 284.43 |
| variance | 533.99 | 533.44 |
| standard deviation | 23.108 | 23.096 |
| min value | 216.73 | 216.69 |
| min (abs) nonzero value | 216.73 | 216.69 |
| max value | 315.58 | 315.5 |
| probability positive | 1 | 1 |
| number of zeros | 0 | 0 |
| 99% real information cutoff bit | 18 | 18 |
| spatial autocorr - latitude | 0.99392 | 0.99392 |
| spatial autocorr - longitude | 0.9968 | 0.9968 |
| entropy estimate | 0.41487 | 0.13675 |
| lossy | |
|---|---|
| max abs diff | 0.12497 |
| min abs diff | 0 |
| mean abs diff | 0.059427 |
| mean squared diff | 0.0035316 |
| root mean squared diff | 0.069462 |
| normalized root mean squared diff | 0.0006603 |
| normalized max pointwise error | 0.0012642 |
| pearson correlation coefficient | 1 |
| ks p-value | 0.36817 |
| spatial relative error(% > 0.0001) | 73.293 |
| max spatial relative error | 0.00048733 |
| DSSIM | 0.97883 |
| file size ratio | 2.98 |
Now we compare mean TS over time in a plot:
[22]:
# comparison between mean TS values in col_TS orig and lossy datasets
ldcpy.plot(col_TS, "TS", sets=["orig", "lossy"], calc="mean")
Below we do a time series plot and group by day of the year. (Note that the group_by functionality is not fast.)
[23]:
# Time-series plot of TS means (grouped by days) in the original and lossy datasets
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "lossy"],
calc="mean",
plot_type="time_series",
group_by="time.dayofyear",
)
Let’s delete the PS and TS data to free up memory.
[24]:
del col_TS
Precipitation Rate
Now let’s open the daily precipitation rate (PRECT) data for 2006-2080 into a collection.
[25]:
# load the last 75 years of PRECT data
col_PRECT = ldcpy.open_datasets(
"cam-fv",
["PRECT"],
[
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/orig/PRECT.daily.20060101-20801231.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/lens/lossy/c.PRECT.daily.20060101-20801231.nc",
],
["orig", "lossy"],
chunks={"time": 500},
)
col_PRECT
dataset size in GB 11.10
[25]:
<xarray.Dataset>
Dimensions: (collection: 2, time: 25100, lat: 192, lon: 288)
Coordinates:
* lat (lat) float64 -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
* time (time) object 2006-01-01 00:00:00 ... 2074-10-07 00:00:00
cell_area (lat, collection, lon) float64 dask.array<chunksize=(192, 1, 288), meta=np.ndarray>
* collection (collection) <U5 'orig' 'lossy'
Data variables:
PRECT (collection, time, lat, lon) float32 dask.array<chunksize=(1, 500, 192, 288), meta=np.ndarray>
Attributes: (12/16)
Conventions: CF-1.0
source: CAM
case: b.e11.BRCP85C5CNBDRD.f09_g16.031
title: UNSET
logname: mickelso
host: ys1023
... ...
history: Tue Nov 3 14:13:51 2020: ncks -L 5 PRECT.daily.2006010...
NCO: netCDF Operators version 4.7.9 (Homepage = http://nco.s...
cell_measures: area: cell_area
data_type: cam-fv
file_size: {'orig': 4909326733, 'lossy': 3446890300}
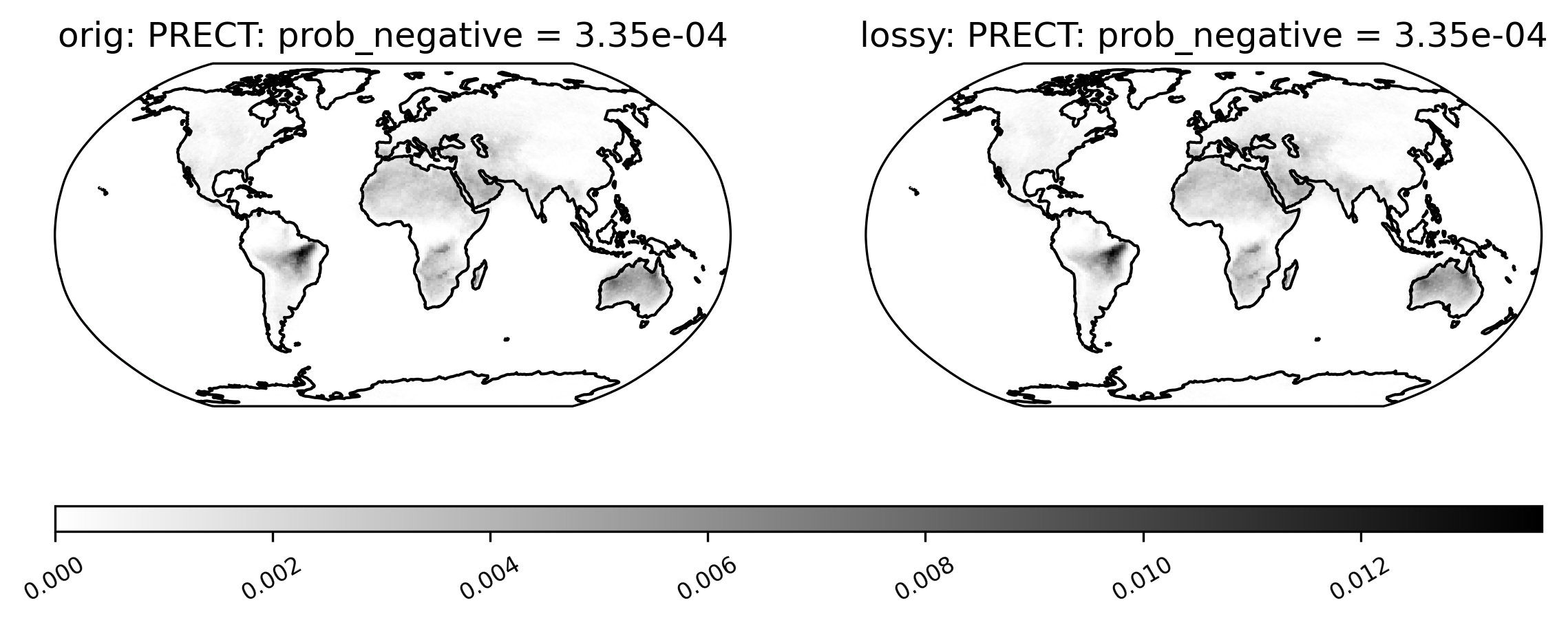
weighted: True[26]:
# compare probability of negative rainfall (and get ssim)
ldcpy.plot(col_PRECT, "PRECT", sets=["orig", "lossy"], calc="prob_negative", color="binary")

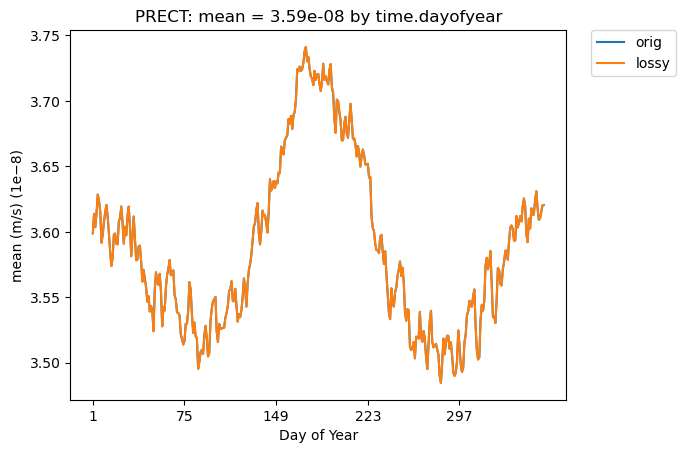
Mean PRECT over time…
[27]:
# Time-series plot of PRECT mean in 'orig' dataset
ldcpy.plot(
col_PRECT,
"PRECT",
sets=["orig", "lossy"],
calc="mean",
plot_type="time_series",
group_by="time.dayofyear",
)

Now look at mean over time spatial plot:
[28]:
# diff between mean PRECT values across the entire timeseries
ldcpy.plot(
col_PRECT,
"PRECT",
sets=["orig", "lossy"],
calc="mean",
calc_type="diff",
)

Calculating the correlation of the lag-1 values … for the first 10 years (This operation can be time-consuming).
[29]:
# plot of lag-1 correlation of PRECT values
ldcpy.plot(col_PRECT, "PRECT", sets=["orig", "lossy"], calc="lag1", start=0, end=3650)

CAGEO Plots
Plots from different data sets used in CAGEO paper (Poppick et al., “A Statistical Analysis of Lossily Compressed Climate Model Data”,doi:10.1016/j.cageo.2020.104599) comparing the sz and zfp compressors with a number of metrics (specified with “calc” and “calc_type” in the plot routine).
[30]:
col_TS = ldcpy.open_datasets(
"cam-fv",
["TS"],
[
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/orig/b.e11.B20TRC5CNBDRD.f09_g16.030.cam.h1.TS.19200101-20051231.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/lossy/sz1.0.TS.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/lossy/zfp1.0.TS.nc",
],
["orig", "sz1.0", "zfp1.0"],
chunks={"time": 500},
)
col_PRECT = ldcpy.open_datasets(
"cam-fv",
["PRECT"],
[
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/orig/b.e11.B20TRC5CNBDRD.f09_g16.030.cam.h1.PRECT.19200101-20051231.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/lossy/sz1e-8.PRECT.nc",
"/glade/campaign/cisl/asap/ldcpy_sample_data/cageo/lossy/zfp1e-8.PRECT.nc",
],
["orig", "sz1e-8", "zfp1e-8"],
chunks={"time": 500},
)
dataset size in GB 16.66
dataset size in GB 16.66
difference in mean
[31]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0", "zfp1.0"],
calc="mean",
calc_type="diff",
color="bwr_r",
start=0,
end=50,
tex_format=False,
vert_plot=True,
short_title=True,
axes_symmetric=True,
)

Zscore
[32]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0"],
calc="zscore",
calc_type="calc_of_diff",
color="bwr_r",
start=0,
end=1000,
tex_format=False,
vert_plot=True,
short_title=True,
axes_symmetric=True,
)

Pooled variance ratio
[33]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0"],
calc="pooled_var_ratio",
color="bwr_r",
calc_type="calc_of_diff",
transform="log",
start=0,
end=100,
tex_format=False,
vert_plot=True,
short_title=True,
axes_symmetric=True,
)

annual harmonic relative ratio
[34]:
col_TS["TS"] = col_TS.TS.chunk({"time": -1, "lat": 10, "lon": 10})
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0", "zfp1.0"],
calc="ann_harmonic_ratio",
transform="log",
calc_type="calc_of_diff",
tex_format=False,
axes_symmetric=True,
vert_plot=True,
short_title=True,
)
col_TS["TS"] = col_TS.TS.chunk({"time": 500, "lat": 192, "lon": 288})

NS contrast variance
[35]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0", "zfp1.0"],
calc="ns_con_var",
color="RdGy",
calc_type="raw",
transform="log",
axes_symmetric=True,
tex_format=False,
vert_plot=True,
short_title=True,
)

mean by day of year
[36]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0", "zfp1.0"],
calc="mean",
plot_type="time_series",
group_by="time.dayofyear",
legend_loc="upper left",
lat=90,
lon=0,
vert_plot=True,
tex_format=False,
short_title=True,
)

standardized mean errors by day of year
[37]:
ldcpy.plot(
col_TS,
"TS",
sets=["orig", "sz1.0", "zfp1.0"],
calc="standardized_mean",
legend_loc="lower left",
calc_type="calc_of_diff",
plot_type="time_series",
group_by="time.dayofyear",
tex_format=False,
lat=90,
lon=0,
vert_plot=True,
short_title=True,
)

[38]:
del col_TS
Do any other comparisons you wish … and then clean up!
[39]:
client.shutdown()
2024-10-31 15:54:46,316 - distributed.deploy.adaptive_core - INFO - Adaptive stop
[ ]: